
It’s not an exaggeration to say that enterprise ready machine identity frameworks are in greater need than before. This is not only because migrating into the cloud brings new challenges, but because there is a greater need in the enterprise scene for the applications to securely discover, authenticate and connect with each other via untrusted networks.
In simple words, we as a business need to secure our data and establish secure links between services just like we used to have in our monolithic/self-hosted environments. If something is leaked, then all the data can be exposed, bringing chaos or indeed dire consequences. Now that we migrate to the Cloud, how can we maintain that source of trust and who can we blame in case things go south?
Unfortunately, in the current scene, it is like swimming in murky waters. We have too many factors to consider and usually, we end up simplifying things. That leads to placing too much knowledge coupling within the apps and microservices – that is, the apps explicitly manage the secrets or configurations values causing them to be harder to change and easier to exploit. Not to mention the extra code that needs to be tested and verified.
I will explain more in this article.
How Service-to-Service Authentication in Cloud Applications is Normally Implemented
Typically, when we develop Applications and Microservices, we keep configuration values that may contain secrets and sensitive values either in environmental variables or using a secrets store like Conjur or KMS. Those variables may be injected at deploy time or at runtime with Summon when our application needs to connect. Once we obtain those secrets, our application can establish outbound connections to other applications.
Outbound connections are those connections established between two hosts or applications in a consumer/producer relationship. For example, a database server such as MySQL is the producer of truth and knowledge of our data, and our Application Server represents the consumer. The application needs to establish a secure connection either directly or via a proxy to the database server. This is why they will require some knowledge of potentially sensitive values from the side of the consumer.
However, as you may have noticed, there are a few cases where this could go wrong:
- Some secrets can be hardcoded in the Application: In the absence of a more rigorous and compliant secrets management solution, it’s very easy to hardcode secrets into the repo or configuration itself. Those secrets are more difficult to track and audit.
- Integration with Secrets Storage engines: Application developers need to integrate with specific secrets store engines, which means they have to add more dependencies and understand their intricacies (or weird behaviors).
- Respond to Changes: If any of the secrets change or are rotated, then our applications need to observe the changes and re-establish their existing connections. Otherwise, a full restart or a different image is required. This could prove problematic sometimes.
Within the Kubernetes ecosystem, there are numerous solutions that have been proposed to simplify service-to-service authentication, such as via tools like Envoy Service Mesh or standards like SPIFFE. However, not all organizations use Envoy or SPIFFE as there is often a long incubation period when adopting new techniques in the enterprise.
How We Should Handle Authentication
Instead of giving the responsibility to the developers to configure and maintain secrets into the application code, we recommend another way: Just don’t implement this functionality at all. When the application requests a secure connection (which may entail some secret values like passwords), then we just intercept this connection request and decorate it with the appropriate connection URI. This way, the whole process become more:
- Transparent: The communication between the consumer service and the producer service is unmanaged by those entities, but rather by a specialized broker that sits between them. This will merely make things work and offer a better abstraction for Authenticated Connections.
- Secure by design: Applications no longer have to contain secrets in their configuration, nor do they need to bundle an API to request secrets in memory. So, there would be fewer attack threats and exposures.
- Integrated: The broker that assigns the secrets can have dedicated integrations with the existing tooling like Vault or KMS. So, we won’t need to change our Secrets Management Solution again.
- Less Maintenance Needed: The maintenance is limited to applying the correct configuration and security permissions between the Broker and the Secrets Store. This could be assigned to the IT Admin or DevOps teams where they have proper training and expertise to assign permissions and rotating secrets. As far as your application knows, they won’t have to deal with secrets again, ever!
Now, you may ask. Is there a tool in the market that does that already? And the answer is, “Yes.” It’s called Secretless Broker. It works by running a Sidecar service next to an App. Below is an example topology that shows how it works: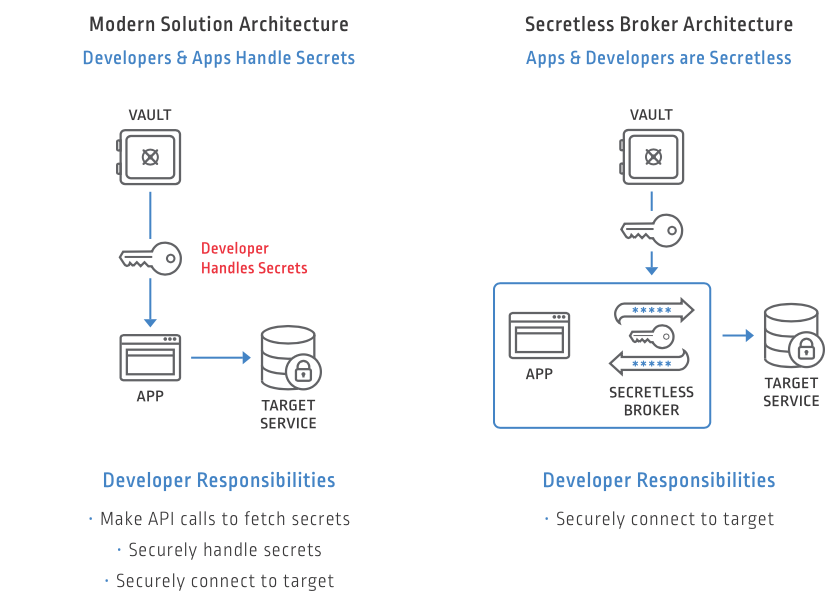
Source: https://developer.cyberark.com/api/secretless-broker/
If you want to learn how to use Secretless in practice, we have a few tutorials – one for Setting up and securing third party MongoDB Secrets using Node.js and another for Kubernetes. This would give you a solid grasp of how to use this tool in practice.
Next Steps
This article represents just an observation of the current situation. As technology evolves and modern challenges arise, then more solutions are found that are regarded as the current “best” way to handle authentication.
We have shown specifically, that when adopting a modern approach such as the Secretless Broker, we can loosen this grip of coupling between services, and offer a more flexible and secure way to communicate securely. Stay put for more articles regarding transparent and reliable authentication between microservices.

Theo Despoudis is a Senior Software Engineer and an experienced mentor. He has a keen interest in Open Source Architectures, Cloud Computing, best practices and functional programming. He occasionally blogs on several publishing platforms and enjoys creating projects from inspiration.