Building a secure AWS environment requires applying security principles and guidelines around the way credentials and sensitive information are shared between resources. This information is not limited to connection strings and API keys — cloud subscription details can lead to unwanted access to your resources, as well.
This blog is a continuation of my previous article, exploring how to provide secure credentials for an EC2 instance using Conjur, deployed within the AWS network.
Here, we will demonstrate how we can query data from DocumentDB using AWS Lambda, and provide access to this data via GraphQL API with AWS AppSync.
We will also see how to connect AWS Simple Email Service (SES) to send email notifications.
The goal of this application configuration is to demonstrate how a complex and stateless cloud-native environment can access secrets from CyberArk Conjur using IAM Authenticator.
Setting up the AWS environment
First, let’s set up the AWS environment to get our resource details so we can update the policies we used in the previous article to run the cluster. We need the following resources and details:
- AWS AppSync (for external apps)
- CyberArk Conjur (on AWS and CLI for secrets management)
- AWS Identity and Access Management (IAM) user account for AWS secrets (we pass these to the Conjur instance)
- AWS DynamoDB (our data source)
- AWS Lambda (for GraphQL resolution and secrets capturing from Conjur)
- AWS SES (for notifications)
If you already have instances on AWS, you can use them here, otherwise create new resources.
AWS AppSync
The API endpoint for our use case will be an AWS AppSync. It connects with additional AWS resources that are deployed on the cloud, notably AWS Lambda. AppSync exposes the services using GraphQL API, which can be accessed with external services.
Visit the AWS AppSync dashboard and create a new AppSync service for this demonstration. You can select any of the templates that are available, but we recommend using the empty template to create a basic service on top of AppSync.
Open the Schemas tab under your AppSync service name, and enter the following schema in the editor:
type Employee {
employee_id: String!
department: String!
}
type Mutation {
putEmployee(employee_id: String!, department: String!): Employee
}
type Query {
# Get an 'Employee' by employee_id.
getEmployee(employee_id: String!): Employee
}
schema {
query: Query
mutation: Mutation
}
We will write our Lambda to be able to provide the data connection for our getEmployee query later.
AWS Lambda and AWS SES
We’ll create an AWS Lambda as a bridge between AppSync and DynamoDB. In the AWS Lambda dashboard, create an empty Lambda. (We recommend using Node.js for a simple Lambda that can be developed in-browser later, but you can use Java or Python as well.)
For AWS SES, we only need to use the credentials (AWS secret keys) to access the AWS SES service from our Lambda and send the email. You can review this blog to learn how to write a Node.js Lambda that can send email using AWS SES. We can provide these secrets to our Lambda using the IAM role and Conjur instance. See the previous article for more on secrets management for IAM roles.
Set Up Lambda as Pipeline Resolver
In AppSync, on the right-side of the Schema, you’ll find the list of current resolvers. Add our Lambda as a resolver here.
Select the default templates that are provided by AWS (Invoke and Forward Arguments) and forward them to your Lambda to query the DocumentDB source.
Now you can write the translation layer between your Lambda and GraphQL to capture the output and present it to the consumer application.
Both sample templates are provided within the AWS dashboard.
DynamoDB as the Data Source
The primary data source, which also hosts our GraphQL service, is DynamoDB. To work correctly, we need to connect a Lambda service to it.
In our example, we are using “employees” as the table name — this conforms with the GraphQL schema. Read the AWS documentation to learn how to read and create objects in DynamoDB using AWS Lambda.
DynamoDB can be accessed using AWS keys for your account. You can create an IAM user (username and password) that will be used later to connect to and access the DynamoDB tables. This helps prevent having to provide elevated access for DynamoDB to our AWS Lambda instance, and we can revoke access anytime by removing the user account from the IAM dashboard.
IAM Role
Now we need to handle the credentials for the Lambda. This can be done in several ways, one of which is attaching a policy that enables our IAM role for Lambda to request secrets from CyberArk Conjur. For guidance on how to attach secrets to an IAM role, read the previous article. To create an IAM user and use their secret and key, create a policy that exposes these as variables.
Deployment of CyberArk Conjur
CyberArk Conjur deployment is in two parts.
The first is deploying within the AWS environment where it can propagate credentials, authenticate requests, and share secrets within the IAM role.
The second is using the Conjur CLI to administer the Conjur instance for your clusters. For example, you can use Conjur CLI to deploy the secrets safely and securely without having to write them in a DevOps pipeline or expose them in version control.
Now set up the environment with CyberArk Conjur on AWS or on your local machine using the CLI.
Deploying the Policy
We can now deploy a policy to our CyberArk Conjur instance to provide it with the AWS credentials of the IAM role used with our Lambda. For more information on how to deploy the policies on Conjur read our previous article, and modify the variables to meet your needs.
- !policy
id: secretApp
body:
- &variables
- !variable aws_secret
- !variable secret_key
# Create a group that will have permission to retrieve variables
- !group secrets-users
# Give the group permission to retrieve variables
- !permit
role: !group secrets-users
privilege: [ read, execute ]
resource: *variables
# The host ID needs to match the AWS ARN of the role we wish to authenticate.
- !host 000000000000/TrustedWithIAMUser
# Add our host to the group for permission to retrieve variables
- !grant
role: !group secrets-users
member: !host 000000000000/TrustedWithIAMUser
This policy contains the variable that contains our AWS secret and key. Read more about variables inside the Conjur policy reference.
We only updated the variables, host, and the member information within the policy. Remember to update the host’s numeric value to match your AWS details for the IAM user/role that you create.
We can now apply this policy using the following command:
# "trusted-with-iam-user.yml" is the file that we created in this process.
conjur policy load conjur/authn-iam/dev trusted-with-iam-user.yml
Reading Data with GraphQL
Let’s test the AppSync service to see if it can access the DynamoDB table and the content using an in-browser GraphQL endpoint. Go to the Queries tab under AppSync service and run a query. We only have a single query endpoint in our schema:
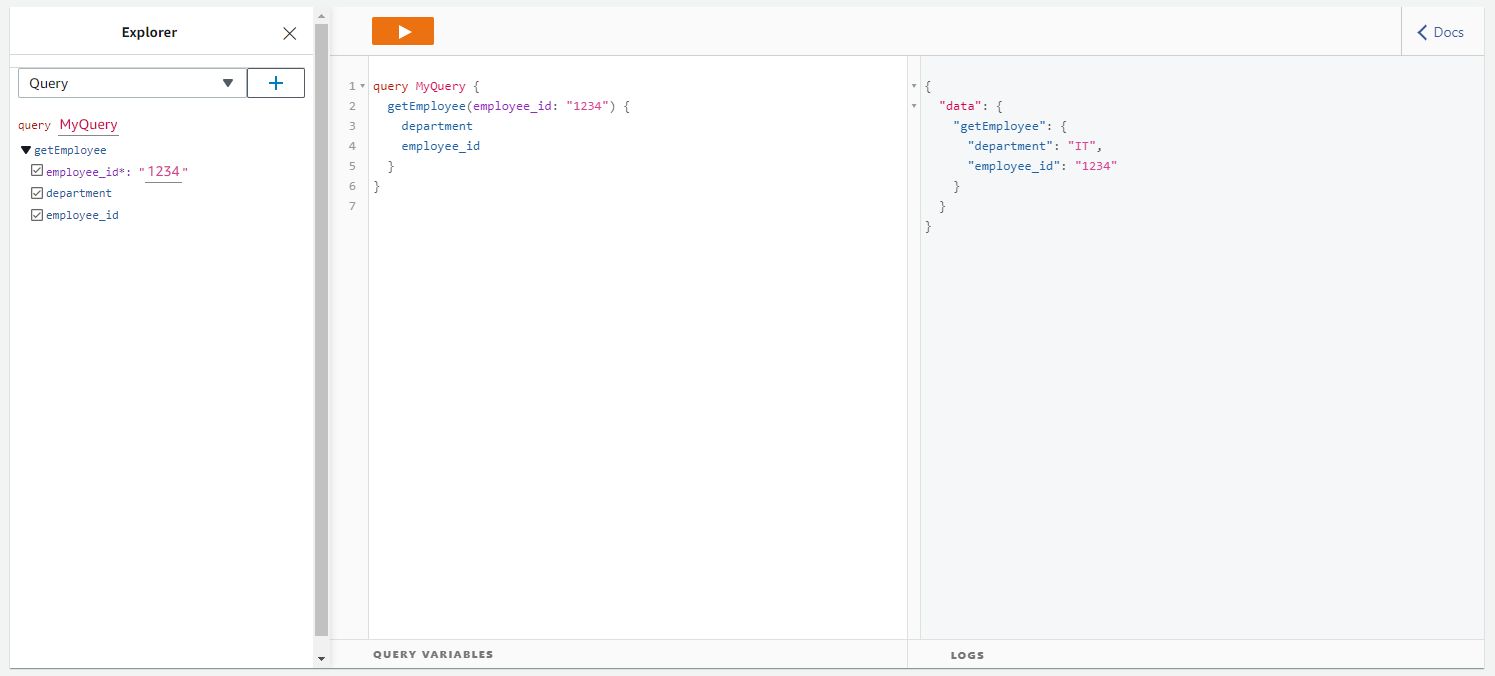
Our GraphQL API fetches the response using Lambda and translates it into a GraphQL response. This confirms that our Lambda can read DynamoDB using the secrets provided to its role.
Wrapping Up
In this article, we connected an AWS Lambda service with AWS DynamoDB and exposed them using AppSync-powered GraphQL APIs.
We used CyberArk Conjur to deploy a policy for our Lambda IAM role to access AWS secrets securely.
We also demonstrated how to mutate the GraphQL queries and pipeline the requests using AWS Lambdas to our internal services within AWS cloud, and add additional request parameters, such as secrets, connection strings, or API keys to the Lambda context.
CyberArk Conjur also prevents a vendor-lock from happening with your credentials and secrets. Because your secrets are stored inside CyberArk Conjur instances, you can move around or remain hybrid.
Explore the Conjur docs to get a deeper look at the many features it offers or check out our interactive Kubernetes tutorial hosted in KataCoda! If you have questions check out our developer community forum.
Joe Garcia is a DevOps Security Engineer with CyberArk. As CyberArk’s automation expert, he enjoys sharing his knowledge with the community through conferences, workshops, videos, and this blog. When not sharing, Joe enjoys learning and tinkering on cutting edge technologies to get ahead of the next big tech wave. Be sure to follow him on Twitter at @Joe_Garcia to see where he’ll end up next.
Comments are closed.